case-study
Fast OCR ONNX Inference Server
Containerized OCR API that stages line segmentation, word segmentation, and CRNN text recognition behind a FastAPI endpoint.
Overview
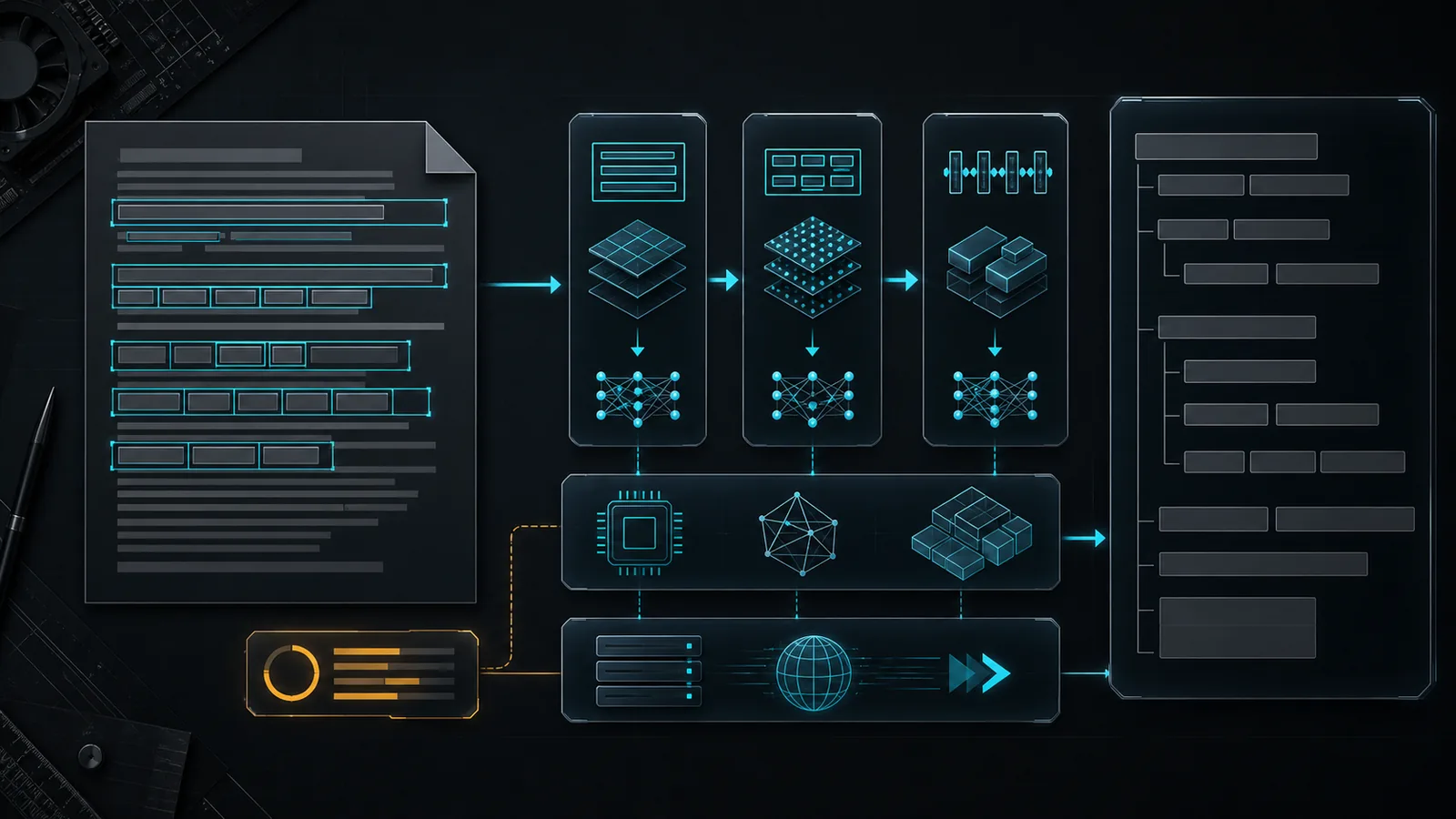
Fast OCR ONNX Inference Server is a public-safe computer vision case study for turning OCR models into a deployable inference service. The pipeline accepts an uploaded image, runs line segmentation, word segmentation, and CRNN recognition, then returns recognized text with line and word boxes as JSON. The public entry focuses on architecture, serving contracts, CPU ONNX runtime, Docker packaging, and response shape.
What It Covers
- Stages OCR as line segmentation, word segmentation, and CRNN text recognition
- Serves inference through a FastAPI upload endpoint with JSON boxes and recognized text
- Packages the model stack for Docker-based CPU deployment
- Documents deployment shape and response contracts with sanitized architecture notes
Stack And Topics
- Python
- FastAPI
- ONNX Runtime
- CRNN
- OCR
- Docker
- Cloud Run
Public Signals
- OCR stages: 3 line segmentation, word segmentation, CRNN recognition
- Model artifacts: 3 line, word, and text-recognition ONNX models
- API endpoints: 2 health check and image inference contract
- Serving target: CPU ONNX containerized FastAPI inference path